Let’s understand Apache Spark
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Why is Spark needed?
Pandas is not recommended for large scale data processing. While Pandas is great for working with small to medium-sized datasets, it can struggle when handling large datasets that don’t fit into memory. This is because Pandas is designed to work with data that can fit into memory on a single machine, whereas Apache Spark is designed to work with data that is distributed across a cluster of machines.
We can run spark on standalone mode, using only one local machine. If the data is just less than 1 gigabytes, which means the machine will be able to process that. But What if we have 10 gigabytes or large data? It will not be able to process it, since local machine will hang when process the data.
In local spark, the master node and worker node are using power of one machine. But if we need to process large data, several machines will be much more capable to do the task.
Spark can run in cluster, where several spark worker nodes work together as one unity, to run large task. These worker nodes are coordinated by spark master node. Each worker node process data chunks in parallel, so the process will be faster. To fully leverage the power of Spark, we will go beyond local computer and run spark cluster in distributed servers.
So, what’s the secret of Spark’s speed?
1️. In-Memory Computation: Spark leverages in-memory processing, where it stores data in memory rather than relying heavily on disk-based storage. By keeping data readily accessible in RAM, Spark eliminates the performance bottleneck caused by disk I/O. This approach enables Spark to deliver blazing-fast data processing and analytics, providing real-time insights.
2️. Distributed Computing: Spark is designed for distributed computing, allowing it to harness the power of a cluster of machines. It divides data and computations across multiple nodes, enabling parallel processing. This parallelization significantly speeds up data operations, as tasks can be executed simultaneously on different machines. Spark’s distributed nature also enables it to scale seamlessly, handling massive datasets without sacrificing performance.
3️. Resilient Distributed Datasets (RDDs): RDDs are a fundamental concept in Spark that contribute to its speed. RDDs enable fault-tolerant and efficient data processing by storing data partitions across a cluster. RDDs allow Spark to recover lost data by tracking lineage information, optimizing execution plans, and minimizing data movement. This optimization strategy ensures high-speed processing while maintaining data integrity.
4️. Lazy Evaluation: Spark adopts a lazy evaluation model, where transformations on data are postponed until an action is triggered. This optimization technique allows Spark to optimize and combine multiple operations, reducing unnecessary computations and minimizing overhead. By deferring execution until necessary, Spark optimizes performance and speeds up processing by executing only the required operations.
5️. Catalyst Optimizer: Spark employs the Catalyst Optimizer, a powerful query optimizer that optimizes the execution plans of Spark SQL queries. Catalyst leverages advanced techniques like cost-based optimization, predicate pushdown, and rule-based optimizations to generate efficient execution plans. This optimization process ensures that Spark executes queries with maximum performance, contributing to its overall speed.
Let’s start working with PySpark (Spark API for Python):
The entry point into all functionality in Spark is the SparkSession class.

In Apache Spark, there are three different APIs for working with big data: RDD, DataFrame, and Dataset. Each API has its own advantages and cases when it is most beneficial to use them.
An RDD (Resilient Distributed Dataset) is the fundamental data structure of Spark representing an immutable distributed collection of objects. RDDs can store any type of data, including structured and unstructured data. It offers low-level operations and lacks optimization benefits provided by higher-level abstractions.

A DataFrame is a distributed collection of data organized into named columns, similar to a table in a relational database and can be manipulated using Spark SQL or the DataFrame API. It is an immutable distributed collection of data.
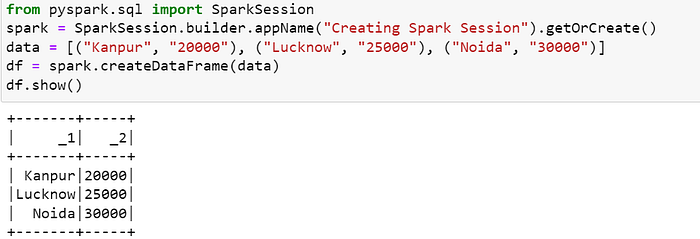
A Dataset is an extension of the DataFrame API, with added features like type-safety and an object-oriented interface.
Note: Dataset API is not available in PySpark as of now. It is only available in the Scala and Java APIs of Apache Spark. We can create a DataFrame instead of a Dataset.
We can use RDDs when you want to perform low-level transformations on the dataset. DataFrames are already optimized to process large datasets for most pre-processing tasks, so you don’t need to write complex functions on your own.
When you submit a Spark application to run on a cluster, the driver program creates a SparkSession that provides a single point of entry to interact with underlying Spark functionality.
The SparkSession communicates with the cluster manager (such as YARN or Mesos) to request resources for your application.
Once resources are allocated, the cluster manager launches executor processes on worker nodes to run tasks and store data for your application.
The driver program divides your application into stages and tasks based on the dependencies between DataFrames or Datasets. Each task represents a single computation on a partition of your data.
The driver program sends tasks to executors to run. Executors run tasks and store intermediate data in memory or disk storage.
When all tasks for a stage are completed, the driver program moves on to the next stage until all stages are completed and your application finishes.
Learn more about Spark architecture here and for Dataframe link
Large cloud providers have spark product, ready to use. The essential installation and configuration already done.
Refer link for running Apache Spark workloads on Dataproc - Google Cloud Platform (GCP)
Feel free to reach out to me over LinkedIn in case of any issues or feedback https://www.linkedin.com/in/aniruddhyadav